[자료의 이해1_기본 용어]
모집단 : 관심 대상의 전체 집합
모수 : 모집단을 분석해서 얻은 결과 (ex 평균, 분산 등)
하지만 실제로는 모집단 전체를 조사하기 힘듦
-> 표본 추출
표본 : 모집단 중 일부
통계량 : 표본을 분석해서 얻은 결과값
통계량을 통해 모수를 추정하자!!
변수형 종류
- 범주형(빈도 분석)
- 명목형
- 단순히 범주(성별, 혈액형)
- 순서형
- 범주의 순서 상대적으로 비교 가능(비만도, 학점)
- 명목형
- 수치형(분포 분석)
- 이산형
- 셀 수 있음. 유한한 범위(멤버의 수, 교통사고 건수)
- 연속형
- 등간형
- 이산형
| 독립 변수 X | |||
| 수치형 | 범주형 | ||
| 종 속 변 수 Y |
수 치 형 |
상관분석 회귀분석 |
t-test |
| 범 주 형 |
로지스틱 회귀분석 |
카이제곱 검정 | |
[자료의 이해2_시각화]
범주형 데이터 - 질적 자료
수치형 데이터 - 양적 자료
일변량차트
: 수치형 데이터->box plot 등을 통해 이상치 알 수 있음. 히스토그램
다변량차트
:수치형&수치형->산점도를 통해 데이터 간의 관계성(선형 관계 등), 데이터가 그룹을 갖고 있는지, 이상치 존재 등을 알 수 있음. But 산점도를 통해 인과관계는 알 수 없음
[통계분석_위치&변이 통계량]
통계량 : 표본을 분석해서 얻는 결과
통계량 종류
1. 위치 통계량
1) 평균
이상치에 민감. 자료 수가 적거나 극단값이 여러 개이면 대푯값 기능 상실
기댓값 E(x)
-평균이 수치형 데이터에 대한 대푯값이라면, 기댓값은 모집단 데이터에 대한 평균값임
2) 중앙값(Median)=중위수
데이터 순서대로 나열->가운데값.(짝수형이면 가운데 두 수의 평균)
이상치에 민감하지 x
3) 최빈값(Mode)
데이터 중 빈도가 가장 많은 값.
질적 변수(명목, 서열 자료)에도 활용 가능.

2. 변이 통계량(산포도=분산도)
자료가 흩어져 잇는 정도를 측정
- 분산
- 두 분포에서 자료의 흩어짐을 비교
- 표준편차
- 원래 자료의 단위로 환원되어 같은 단위로 측정된 다른 통계량과 쉽게 비교 가능
특징
- 자료가 흩어질수록 범위, 분산, 표준편차 커짐
- 자료가 평균 주위로 집중하면 범위, 분산, 표준편차 작아짐
- 자료 모두 동일 -> 범위, 분산, 표준편차=0
- 변동계수(CV)
- 표준편차를 평균으로 나눈 값.
- 서로 다른 데이터 간의 편차 비교
표준편차는 키가 커서 자료의 키의 데이터가 더 흩어져있다고 생각할 수 있지만 키와 몸무게의 스케일이 다르기 때문에,
표준편차를 평균으로 나눴을 때 확인해보면 몸무게의 변동계수가 더 큼을 알 수 있음->몸무게의 데이터가 더 퍼져있음
3. 모양 통계량(분포의 모양)
- 데이터 분포의 형태와 대칭성 설명
- 왜도(skewness)
- 분포의 대칭성 알아봄
- 첨도(kurtosis)
- 정규분포 대비 봉오리의 높이 알아봄
[통계분석_확률&베이즈 정리]
표본공간(Sample space) : 확률실험으로부터 가능한 모든 결과들의 모임
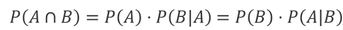
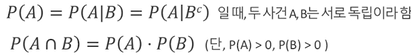
베이즈 정리
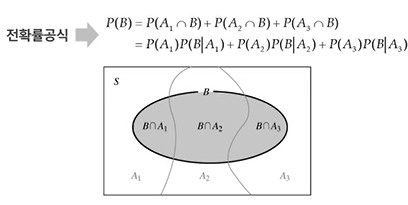
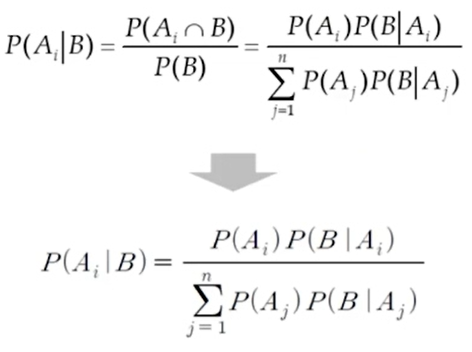
[주요확률분포1_이산, 연속, 균등, 이항, 포아송, 지수]


* 이항분포
베르누이 실험에 기초.
조건
- n번 독립적으로 시행.
- 성공/실패
- 1번 시행 시 성공확률 p. 실패확률 (1-p). 확률은 시행때마다 동일
- 확률변수 X : n번 시행 중 성공횟수
특성
- 성공확률 p=1/2에 가까움->좌우대칭 종모양
- n이 크면 p의 크기에 관계 없이 좌우대칭
- n이 작고 p<1/2이면 오른쪽 꼬리 분포
- n이 작고 p>1/2이면 왼쪽 꼬리 분포
* 포아송분포
특정한 단위 안에서 발생되는 횟수의 값을 알아낼 때 사용.
포아송분포의 람다값이 커질수록 정규분포에 수렴.
* 지수분포
사건 독립. 일정시간동안 발생하는 사건의 횟수가 포아송 분포를 따를 때, 다음 사건이 일어날 때까지의 대기시간
람다가 커질수록. 일정시간동안 사건이 많이 발생할 수록 대기시간은 짧아진다.
[주요확률분포2_정규, t, 카이제곱, f]
* 정규분포
- 연속확률변수를 기술하는 가장 중요한 확률분포
- 종 모양
- 중심극한정리에 의해 독립적인 확률변수들의 평균은 정규분포에 가까워지는 성질이 있기 때문에 수집된 자료의 분포를 근사하는 데에 자주 사용
- 중심극한정리 : 각각의 표본에서 평균을 구한 뒤, 이 평균들을 원소로 하여 이 표본평균들의 평균을 구하면, 모집단이 어떤 분포를 따르던지, 표본의 평균들은 무조건 정규분포를 따른다.
- 표준정규분포 : 정규분포 표준화. 평균=0, 분산=1인 정규분포
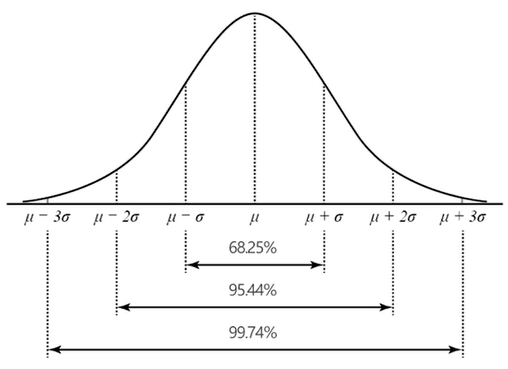
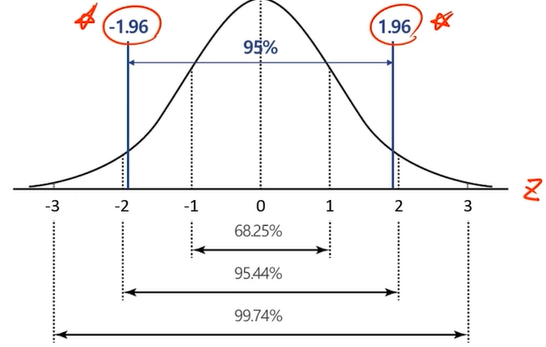
* t분포(Student's t-Distribution)
- 활용
- 모집단 평균 추론 시 표본의 수가 적을 경우(보통 30개 미만)
- 모집단의 분산을 모를 경우, 가설검정, 회귀분석시
- 선형 회귀 계수 추론
- 정규분포와 유사하게 좌우대칭 종모양. 중심=0
- 자유도에 따라 형태가 다름
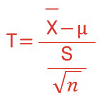
이때 분모는 표준오차를 의미.
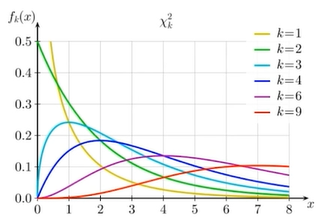
* 카이제곱 분포(Chi-squared Distribution)
- 활용
- 모집단 분산 추론 시
- 카이제곱 검정 시
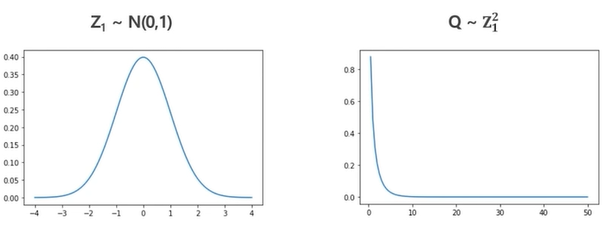
- 자유도가 k인 x^2분포의 평균은 k, 분산은 2k
- 항상 양수. 심하게 왼쪽으로 쏠린 분포임. 자유도에 따라 모양 변함. 자유도가 커질수록 정규분포에 가까워
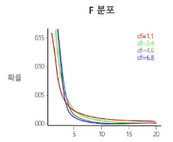
* f분포
- 활용
- 두 모집단 분산차이 비교 시
- F-검정, 분산분석, 회귀분석 등
- 분산떠올리기. 회귀 때 사용
- 분산의 비를 이용해 특징 추출
- 이 분산비를 활용해 두 분산 간의 동질성 여부 검정 or 두 개 이상의 평균치 간의 차이 유무 검정(F-검정, 분산분석, 회귀분석 등)
- 두 개의 자유도에 따라 모양 달라짐. 항상 양의 값만 가짐. 왼쪾으로 치우친 비대칭 형태.
- 자유도가 커질수록 정규분포에 가까워

[추론 통계1_추정]
* 추정
모집단의 평균, 분산, 표준편차 등을 표본을 이용해 알아내려는 과정
추정량 : 추정때 사용되는 통계량. 표본에서 나옴. (가설점정에서는 검정통계량으로 부름)
추정치 : 추정량을 평가해 얻는 수치
* 점추정
- 모집단의 특성을 하나의 값으로 추정.
- 표본으로부터 표본평균, 표본분산 등을 얻음.
- 표본이 모집단 특성을 잘 표현하지 못하면 오차 클 수 있음
- 사전에 조건들이 갖춰져있어야 그 값이 맞다고 인정할 수 있음.
- 조건 : 모집단을 잘 대표하는 표본을 추출해야함. 분산도 작아야함 등..
-> 구간추정 많이 사용
* 구간추정
- 표본 안에 오차가 있다고 전제.
- 모수가 포함될 것이라고 추정하는 범위를 나타냄
- 구간 설정 : 구간이 좁으면 좀 더 모수를 정확하게 추정
- 신뢰도 설정 : 설정된 구간 안에 실제 모수가 존재할 확률
- 구간의 상한/하한 내에 표본평균이 존재
* 대수의 법칙 / 중심극한정리
대수의 법칙 : 표본수가 많을수록 오차는 줄어듦
중심극한정리 : 표본이 커지면 표본들의 평균은 정규분포를 따르게 된다
* 신뢰구간
- 모수가 특정 확률로 포함될 것이라고 주장하는 범위
- 신뢰구간 추정치 : 하한 ≤ 점추정치 ≤ 상한

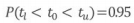
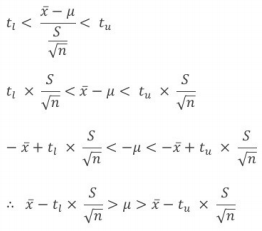
이때 z분포나 t분포나 계산식은 동일함. z분포인지, t분포인지에 따라 신뢰구간의 상한, 하한값이 달라짐
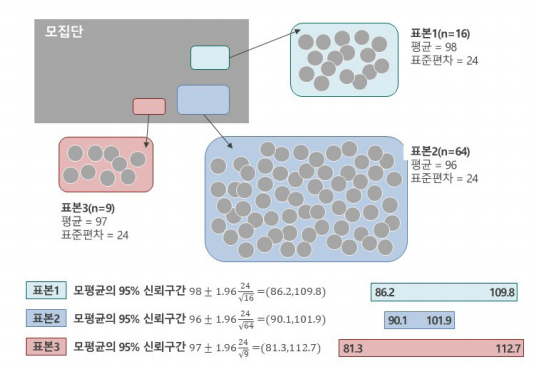
신뢰구간이 좁을수록 정확도가 높다.
모집단의 평균이 좁은 신뢰구간에 위치한다는 뜻임. => 성능이 높다
* 신뢰수준
- 모수의 참값이 두 신뢰 한계 안에 포함될 것이라고 주장할 때 사용하는 확률
- 90%, 95%, 99% 신뢰수준 주로 사용
- 모수 뮤에 대한 95% 신뢰구간이란, 모수 뮤가 이 구간에 들어갈 확률이 95%라는 것이 아니라!!!!!!!!!
- n번을 반복추출하여 산정하는 수많은 신뢰구간 중에서 평균적으로 95%는 모수 뮤를 포함하고 있을 것이라는 의미
* 표준 오차(Standard Error)
- 오차.
- 표준 오차는 표본 평균의 퍼짐 정도(표본평균의 표준편차)

- 표준편차 vs 표준오차
- 표준편차 : 원시 자료의 퍼짐 정도에 대한 측도
- 표준오차 : 표본평균의 퍼짐 정도(표본평균의 표준편차)
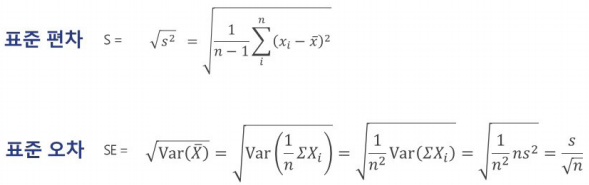
- 표준편차와 표준오차를 통해 실험에서 사용할 샘플의 개수 정할 수 있음

'Data > Python' 카테고리의 다른 글
| [Data/Python] 비계층적 군집분석 (1) | 2024.01.25 |
|---|---|
| [Data/Python] 상관분석 (0) | 2024.01.24 |
| [Data/Python]실습_데이터 전처리: 결측치 이상치 (0) | 2024.01.17 |
| [Data/Python]실습_표본 추출 (0) | 2024.01.17 |
| [Data/Python]실습_EDA: 수치형, 범주형 기술통계 (0) | 2024.01.17 |

